In this article an approach to the token balance accounting is presented. This is a development of the ideas presented earlier taking into account the upcoming contract metadata standard TZIP-16.
In a few words, there is a problem when indexing operations that alter token balances: if the invoked method is not standardized (currently we have only FA1.2/FA2 transfer), or if there is an initial token distribution at the origination — it's not possible for the indexer to determine which particular balances have changed and how.
ULTIMATE GOAL
Get the list of changed token balances from the operation content and result.
The current approach is using custom handlers for known contracts. Obviously, it is tied to a specific indexer implementation and is not scalable, so we need a better alternative that is:
- Flexible enough to cover the majority of cases;
- Simple enough to implement/integrate with existing codebase;
- Not tied to any specific entity nor implementation.
# Off-chain events
The solution lies on the surface: we need to take all the custom logic out of the indexer, as well as to give the developers of the contracts the opportunity to edit it themselves.
This is effectively the concept of external (off-chain) views: a piece of Michelson code that is applied to the contract storage. Actually, one can write those external scripts in LIGO, SmartPy, Lorentz, or other high-level language and then compile down to Michelson.
The upcoming TZIP-16 standardizes off-chain views and defines two kinds that can be used in the contract metadata.
NOTE
The task of indexing metadata is beyond the scope of this article, we simply assume that for a particular contract we have a TZIP-16 compliant data file.
The existing view kinds are not enough for our needs, so we suggest adding some new ones. Below we will list cases that require the use of off-chain views, and the according implementation examples.
DEFINITION
In this article we use the term off-chain event (suggested by Seb Mondet) implying that this is a workaround until a native event logging system is implemented (suggested by Gabriel Alfour).
# Initial storage
Let us consider a case when tokens are pre-minted and distributed when deploying a contract.
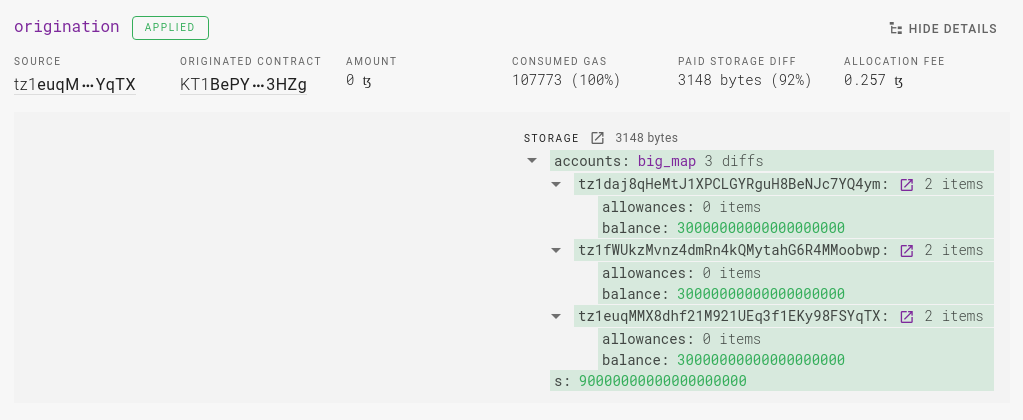
Except for the case when the entire ledger is copied from another contract (Big_map copy, we'll deal with it later), everything we need is in the resulting storage (Big_map items are already included).
Let's take the storage type of the sample contract above:
pair
(big_map %accounts address
(pair (map %allowances address nat) (nat %balance)))
(nat %s)
The according event script would have:
unitparameter type;- Storage type similar to one in the target contract, except all
big_mapoccurrences are replaced bymap; - Code must end with a
FAILWITHinstruction and there must be a value of typemap address balanceon top of the stack.
This value is actually all the balances changed during a contract call, and for each change indexer needs to know:
- Holder address;
- Token ID (in case there are more than one token within the contract);
- Resulting balance.
Note that we can omit token ID e.g. for FA1.2 or other contracts with a single token. Otherwise we have to put map (pair address nat) nat instead.
Here is a script that derives token balances from the given contract storage:
parameter unit;
storage (pair
# we changed `big_map` to `map` to be able to iterate
(map %accounts address (pair (map %allowances address nat) (nat)))
(nat %s));
code {
CDAR ;
MAP { CDDR } ;
FAILWITH
}
Invoking the script with Unit parameter and origination storage we get an expected runtime error with:
{ Elt "tz1daj8qHeMtJ1XPCLGYRguH8BeNJc7YQ4ym" 30000000000000000000 ;
Elt "tz1euqMMX8dhf21M921UEq3f1EKy98FSYqTX" 30000000000000000000 ;
Elt "tz1fWUkzMvnz4dmRn4kQMytahG6R4MMoobwp" 30000000000000000000 }
Finally, the metadata file would look like:
{
"version": "1.0.0",
"license": "MIT",
"authors": ["Unknown"],
"interfaces": ["TZIP-7"],
"views": [{
"name": "get-changed-token-balances",
"description": "Get changed token balances from the operation receipt.",
"pure": "true",
"implementations": [{
"michelson-initial-storage-token-event": {
"storage": {"prim": "pair", "args": [...]}, // modified storage type
"return-type": {"prim": "map", "args": [{"prim": "address"}, {"prim": "nat"}]},
"code": [{"prim": "CDR"}, {"prim": "CAR"}, ... , {"prim": "FAILWITH"}]
}
}]
}]
}
Note that we have a single view item that is responsible for deriving token balance updates and multiple implementations which are used depending on the situation.
# Extended storage
In our previous article we proposed to derive token balance updates directly from big_map_diff data (array of Big_map changes attached to the operation receipt). However this approach is a bit limiting and becomes a problem in case there is a need to access other parts of the contract storage in order to calculate token balances. Also, one need to implement batching for minimizing the number of Michelson script invocations.
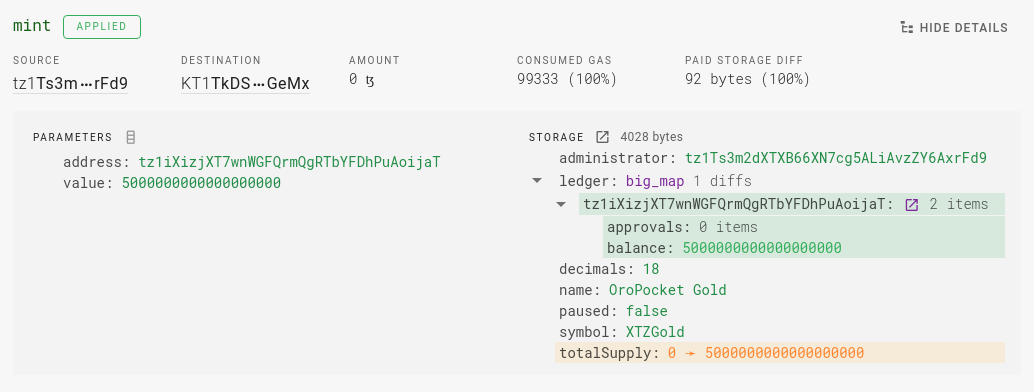
Instead we propose to use something we call extended storage which is essentially big_map_diff items merged into the resulting storage attached to the operation receipt. It works like the following, say we have resulting storage containing a Big_map pointer (integer number):
## storage type
pair
(pair (address %administrator)
(pair
(big_map %ledger address
(pair (map %approvals address nat) (nat %balance)))
(int %decimals)))
(pair (pair (string %name) (bool %paused))
(pair (string %symbol) (nat %totalSupply)))
## storage value
Pair (Pair 0x00005a374e077b2e539f222af1e61964d7487c8b95fe (Pair 66 18)) ## Big_map 66
(Pair (Pair "OroPocket Gold" False) (Pair "XTZGold" 5000000000000000000))
In addition to that we have an array of changed Big_map items:
"big_map_diff": [{
"action": "update",
"big_map": "66",
"key_hash": "exprus2Taan1pH5Xdx2zp1hBXvLxHwSYm14DH1p1Af4PegCartdjgV",
"key": {
"bytes": "0000fb19a008a4efd45fdca1b4fef4f845819b730d2e"
},
"value": {
"prim": "Pair",
"args": [[], { "int": "5000000000000000000" }]
}
}],
The algorithm is:
- Group Big_map items by ID
- Wrap Big_map values in
option:Some valueif value is not null, elseNone - Convert each group to a sequence of elements
{ Elt key (Some value) ; ... ; Elt key_n None } - Using original storage type as a guidemap replace all Big_map pointers with according sequences, effectively changing types from
big_map k vtomap k (option v)
The event script that derives token balances from such extended storage will look like:
parameter unit;
storage (pair
(pair (address %administrator)
(pair
(map %ledger address ## big_map changed to map
(option (pair (map %approvals address nat) (nat)))) ## wrapped
(int %decimals)))
(pair (pair (string %name) (bool %paused))
(pair (string %symbol) (nat %totalSupply))));
code {
CDADAR ;
MAP { CDR ; IF_SOME { CDR } { PUSH nat 0 } } ; ## None means zero balance
FAILWITH
}
And after applying the script to the extended storage we get:
{ Elt "tz1iXizjXT7wnWGFQrmQgRTbYFDhPuAoijaT" 5000000000000000000 }
The according TZIP-16 event kind:
...
"implementations": [{
"michelson-extended-storage-token-event": {
"storage": {"prim": "pair", "args": [...]}, // modified storage type
"return-type": {"prim": "map", "args": [{"prim": "address"}, {"prim": "nat"}]},
"code": [{"prim": "CDR"}, {"prim": "CAR"}, ... , {"prim": "FAILWITH"}],
"entrypoints": ["mint"] // optional field, defines the scope for this particular event kind
}
}]
...
The extended storage approach may seem overcomplicated for this particular contract example, but we have to realize that since there are no storage type restrictions (and there shouldn't be!) the event script can be of arbitrary complexity. As proof take a look at the tzBTC view implementation from our previous post.
# Transaction parameters
So far, we have studied scripts working with the contract state. However, by analogy with standardized entrypoints, in some cases we can judge the change in token balances by transaction parameters (sometimes it's the only sane option).
Let's say we have a contract call with the following parameters:
"parameters": {
"entrypoint": "mint",
"value": {
"prim": "Pair",
"args": [{"string": "tz1RmD9igqvhQ4FkWw7GMQxxoenvHj6N478g"}, {"int": "7800"}]
}
}
In this particular example we have everything we need to derive a balance update, destination address and amount. The parser script will be a bit different from the previous ones though:
- Storage is no longer used (of type
unit); - Parameter type must implement a subset of the original contract entrypoints (in our case
mint); - Script can "return" nothing (
Unit) in case a non-handled entrypoint is called.
storage unit;
parameter (or (pair %mint (address %address) (int %amount)) (unit %fallback)) ;
code {
CAR ;
IF_LEFT { EMPTY_MAP address int ;
SWAP ;
UNPAIR ;
DIP { SOME } ;
UPDATE }
{ UNIT } ;
FAILWITH
}
All we have to do next is to forward our contract call to the event script:
{ Elt "tz1RmD9igqvhQ4FkWw7GMQxxoenvHj6N478g" 7800 }
Everything would be fine, but this particular event implementation can be broken due to the lightweight nature of entrypoints in Michelson. In case the original contract call does not specify the entrypoint we won't be able to handle it correctly:
"parameters": {
"entrypoint": "default",
"value": {
"prim": "Left",
"args": [{
"prim": "Left",
"args": [{
"prim": "Right",
"args": [{
"prim": "Right",
"args": [{
"prim": "Pair",
"args": [
{"string": "tz1RmD9igqvhQ4FkWw7GMQxxoenvHj6N478g"},
{"int": "7800"}
]
}]
}]
}]
}]
}
}
There are basically two ways to mitigate this:
- Use the entire contract parameter type in the event script;
- "Normalize" transaction parameters before forwarding to the event script.
The latter will be reviewed in details in the next section.
Summing up, our TZIP-16 view definition would look like the following:
...
"implementations": [{
"michelson-parameters-token-event": {
"entrypoints": ["mint"],
"parameter": {"prim": "or", "args": [...]}, // modified parameter type
"return-type": {"prim": "map", "args": [{"prim": "address"}, {"prim": "nat"}]},
"code": [{"prim": "CAR"}, {"prim": "IF_LEFT", "args": [...]}, {"prim": "FAILWITH"}]
}
}]
...
Note the extra "entrypoints" field that helps to filter out contract calls we don't want to handle.
# Parsing transfers
We have finished with off-chain events and moving on to the standardized contract methods that alter token balances. There shouldn't seem to be any problems here, however the devil is in the details 😈
Here is a real example of tzBTC transfer call:
"parameters": {
"entrypoint": "default",
"value": {
"prim": "Right",
"args": [{
"prim": "Right",
"args": [{
"prim": "Right",
"args": [{
"prim": "Right",
"args": [{
"prim": "Left",
"args": [{
"prim": "Right",
"args": [{
"prim": "Right",
"args": [{
"prim": "Left",
"args": [{
"prim": "Pair",
"args": [
{"bytes": "00009472982d7f6b096bc57d6da95e0b8ec8ee37e72f"}, // from
{
"prim": "Pair",
"args": [
{"bytes": "0000bf97f5f1dbfd6ada0cf986d0a812f1bf0a572abc"}, // to
{"int": "10000"} // amount
]
}
]
}]
}]
}]
}]
}]
}]
}]
}]
}
}
The thing one should always remember when dealing with Michelson is that there can be more than one way to call a particular contract method.
Another thing that might caught your eye is that source and destination addresses are in a byte form. This also should be considered: Micheline values can be returned both packed or unpacked, and you have to be ready to properly handle that.
# Normalizing parameters
Citing the documentation:
A contract with entrypoints is basically a contract that takes a disjunctive type (a nesting of or types) as the root of its input parameter, decorated with constructor annotations (starting with %).
The concept of entrypoints is very lightweight in Michelson, and under the hood it's still a value of a single type that is actually passed to the script. Hence the various ways to do the same thing, e.g:
KT1VG2WtYdSWz5E7chTeAdDPZNy2MpP8pTfL (Left (Left ($Arg)))
KT1VG2WtYdSWz5E7chTeAdDPZNy2MpP8pTfL%default (Left (Left ($Arg)))
KT1VG2WtYdSWz5E7chTeAdDPZNy2MpP8pTfL%fund (Left ($Arg))
KT1VG2WtYdSWz5E7chTeAdDPZNy2MpP8pTfL%initiate ($Arg)
What we want to do is to find such entrypoint that have the shortest argument type.
In order to do that one need to build a two-way lookup table containing all contract entrypoints and corresponding Micheline wrappers. This can be achieved by traversing the contract parameter type tree, e.g.:
| Entrypoint | Wrapper |
|---|---|
| root | $arg |
| default | Left ($arg) |
| A | Left (Left ($arg)) |
| B | Left (Right ($arg)) |
| C | Right (Left ($arg)) |
The proposed algorithm is not optimal, but most demonstrative:
Stage one: descending
- Retrieve wrapper by the "entrypoint" specified in transaction parameters;
- Wrap the "value" field: we now have a value of type
parameter.
Stage two: ascending
- Find entrypoint that have the corresponding wrapper;
- If found, unwrap the value and construct new parameters.
%default (Left 42) # original transaction parameters
%root (Left (Left 42)) # descending
%A 42 # ascending
This leads to a disappointing conclusion: in order to index token transfers one will have to normalize ALL contract calls.
# Unhandled cases
Even though we have covered many cases, it may still be that off-chain events cannot help.
# Big_map copying
In Michelson you can copy the entire Big_map from another contract by pointer, and in this case big_map_diff receipt will contain only a single copy item without updates (that makes sense since there can be too many items to display/process).
Now imagine two cases:
- FA contract is being originated with copying all token holders from another contract (e.g. upgrade or airdrop);
- Token balance ledger is being edited by replacing with another ledger (this is a real scenario).
In theory we can manually derive changed Big_map items if we have all data indexed (actually we do that in BCD), but it's obviously an overhead for our particular task.
The question how to deal with such cases is still open, it seems logical trying to avoid working with Big_maps i.e. prefer "parameter events" over "extended storage events", however it's not always possible.
# Random Big_map access
There might be cases when in order to calculate balances one need to access some variable stored in a Big_map (that is not changed during the call thus not it the big_map_diff). This particular case is not covered by neither of the event kinds we listed, and would require an additional context call which is undesirable. The intention is to make off-chain events unattached to the blockchain context so that all you need is an operation receipt and a Michelson interpreter.
# Dynamic balances
There are cases when the suggested approach to indexing tokens won't work. For example some balances may depend on the current timestamp.
Generally, it's not clear how to do accounting for such cases, currently we are thinking of an approach similar to the one used for handling trading positions. However, that might be not intuitive for end-users and bring misunderstanding.
# Usage
Let's put everything together and see how one can apply that in practice. As was mentioned earlier, storing and indexing contract metadata is left beyond the scope of this article, so we assume we can query it from somewhere at little cost at runtime.
# Input
Our algorithm receives an operation group with metadata (operation results) from the Tezos node. This can be either an indexer iteration or a result of the run_operation simulation run by a wallet in order to estimate fees.
An operation group can have multiple contents each of which includes the main operation and optionally several internal ones:
{
"hash": "opV1tP31WJrh55R5jaWWTSidBppu61o914SfasNtcmuKH5AGubE",
"contents": [{
"kind": "transaction",
"parameters": {
"entrypoint": "default",
"value": { ... }
},
"metadata": {
"operation_result": {
"storage": { ... },
"big_map_diff": [ ... ],
"originated_contracts": [ ... ],
...
},
"internal_operation_results": [{
"kind": "transaction",
"parameters": { ... },
"result": {
"storage": { ... },
"big_map_diff": [ ... ],
"originated_contracts": [ ... ],
...
},
...
}]
...
},
...
}],
...
}
By operation receipt we will mean a set of kind, status, parameters, resulting storage, big_map_diff, and originated_contracts. This also means that every internal operation result is also an operation in our understanding.
# Handling origination
This is a simple case, if there is an off-chain event of kind michelson-initial-storage-token-event assosiated with the originated_contract — fire it.
# Handling transaction
First thing we should do is normalize transaction parameters. After that the following logic is applied:
- If it is a
transfer(entrypoint name and type match) — parse transaction parameters; - For each off-chain event assosiated with the destination if entrypoint is in the event scope (or scope is undefined) fire that event.
# Firing event
We will use the run_code RPC endpoint for the event script execution:
POST /chains/main/blocks/head/helpers/scripts/run_code
{
"script": [
$event.parameter || {"prim": "parameter", "args": [{"prim": "unit"}]},
$event.storage || {"prim": "storage", "args": [{"prim": "unit"}]},
$event.code
],
"storage": $receipt.storage || merge($receipt.storage, $receipt.big_map_diff) || {"prim": "Unit"},
"input": normalize($receipt.parameters).value || {"prim": "Unit"},
"entrypoint": $receipt.parameters.entrypoint,
"amount": "0",
"chain_id": $network.chain_id,
}
Tezos node returns Internal Server Error [500] and a list of errors.
# Parsing errors
We need to extract the FAILWITH argument: it's stored under with key within the script_rejected error.
[
{
"kind": "temporary",
"id": "proto.006-PsCARTHA.michelson_v1.runtime_error",
"contract_handle": "KT1BEqzn5Wx8uJrZNvuS9DVHmLvG9td3fDLi",
"contract_code": [ ... ]
},
{
"kind": "temporary",
"id": "proto.006-PsCARTHA.michelson_v1.script_rejected",
"location": 42,
"with": { ... } // <-- THIS IS WHAT WE NEED
}
]
# Application
Currently we see two potential use cases for off-chain events:
- Token balance accounting (tracking all token mints, transfers, burns, etc.)
This enables querying balances for a particular holder at any point in time, calculating supply, making reports, and other things. - Token balance receipts (similarily to
balance_updates)
This feature can improve wallet UX and security serving as a "what if" evaluator. Useful for complicated calls when it's hard to understand the outcomes of the operation.
# Conclusion
Time to wrap things up and summarize. The approach to the token balance indexing we suggest seems to be:
- Decentralized enough not to be tied to a specific implementation, database, or entity, still can be launched rather quickly with minimum efforts from other community members and contract developers;
- Not tied to certain token standards, which gives a margin of safety for the future and will also minimize the legacy.
Pros
- Very flexible (new event kinds can be introduced)
- No additional gas / storage costs (comparing to global event sink approach)
- Has retroactive effect (can be applied to already deployed contracts)
Cons
- Extra RPC calls (however not too many since most cases will be
transfers) - Requires metadata indexing (or using external metadata store)
- A relatively complicated integration (into an indexer or a wallet)
# References
- External views, Gabriel Alfour
- The Fatootorial, Seb Mondet
- TZIP-16 Metadata standard, Seb Mondet
- Deriving FA token balance_updates from big_map_diff, Michael Zaikin
# Revisions
- 28 Aug'20 Initial publication
- 30 Aug'20 Fixed Big_map item removal case (extended storage), added random Big_map access case (unhandled) [thanks to Tom Jack]