
Welcome to the Baking Bad podcast dedicated to the development process of TzKT — a lightweight, API-first, account-oriented block explorer based on its own indexer and supported by the Tezos Foundation.
In the previous article, we discussed several hypotheses about an ideal block explorer and it’s time to demonstrate a bit of practice. In this article we’re going to discuss the architecture of the TzKT explorer, its pros and cons, and why did we choose one or another approach. Let’s begin.
# General picture
TzKT consists of three main components: blockchain indexer, API service and frontend part. Combining them together, we get the following picture.

It’s worth noting that every component is made as a separate and independent service. That’s actually pretty good because it enables consumers to use only the needed components or even replace some with their own.
Such microservice architecture is not only flexible but also has great horizontal scalability. While one working indexer is enough for collecting data, one API server or even one database instance may not be enough (depending on system load) for providing high-quality service.
So the result may look as follows.
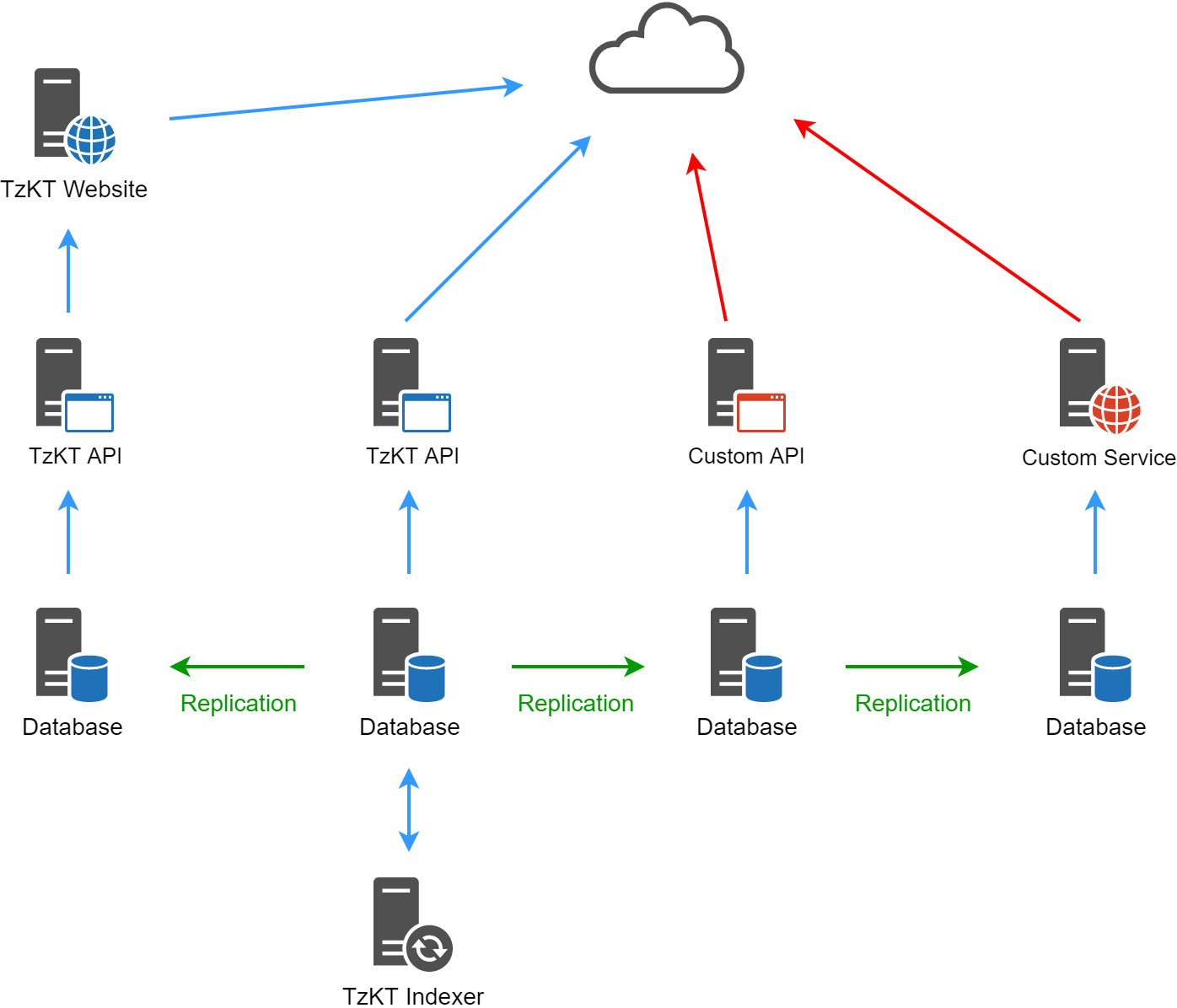
Now let’s take a look at indexer and API components in detail.
# TzKT Indexer
Under the hood, an indexer is a simple loop that processes each block from the blockchain.

But, as we know, Tezos experienced several protocols (and there will be many more protocols in the future), which means that different blocks must be validated and processed differently, depending on the particular protocol.
# Protocol handlers
Initially, we planned to create a flexible and extendable protocol handler, but when we realized that there were too many breaking changes between Tezos protocols (even RPC responses had different schema) we decided to create separate protocol handlers for each Tezos protocol. So that we don’t really care about changes in the Tezos proposals, but we have to write much more repetitive code. We believe it’s worth that.
So the first step of the cycle is to determine the protocol handler. After that, the chosen protocol handler deserializes and validates the block.
# Blocks validation
When the block is deserialized we want to make sure that it contains correct/expected values. For example, if a Babylon’s block has priority 0 and includes 32 endorsements, the baker receives 16 tez reward, not 15.9 nor 16.1, etc. On the other hand, blocks validation is necessary to test our knowledge of the current protocol, so if there is an unexpected value, then we probably missed something during a protocol handler implementation.
# Committing changes
When the block is validated, we “split” it into a bunch of atomic commits, which can be applied or reverted, in case of canceling the last block.
In substance, each commit represents one particular feature of the indexer. For example, if we want to store transactions, we create a transaction commit, which extracts all transactions from the block, processes them and saves to the database. Or, if we want to collect statistics, we create an appropriate commit that fetches required data from the block processes and saves it.
To be honest, it’s quite convenient to add features to the indexer with this approach.
# Diagnostics
There is also an option to do self-diagnostics before applying or reverting commits. This option is needed to ensure that the protocol handler did everything correctly. But as a side effect, it makes extra RPC calls (which, incidentally, are very slow) so it should be disabled during synchronization with the blockchain. Otherwise, it will take a long time.
After completing these steps, changes are saved to the database, and the indexer begins to wait for the next blocks.
# A bit of sweets
TzKT indexer consumes around 70MB RAM (with a peak of 100MB during full synchronization) and around 5GB of disk space at the end of the 173rd cycle of the Tezos mainnet (1GB data + 4GB indexes). Endorsement operations take 80% of that 😆.
Also, there is no need to synchronize the indexer from the genesis because we are going to provide recent snapshots (~800MB at the moment) to enable consumers to bootstrap it as fast as possible.
# TzKT API
In addition to the TzKT Indexer, we are also developing a native API to provide a convenient way to access the data. It’s simpler and much faster (due to smart caching) than querying the database directly.

As you can see TzKT API uses not only the indexer database but also additional data sources/providers, which allows us to enrich the answers with useful metadata, e.g. address aliases, proposal descriptions, etc. This also means that the API can be easily customized for anyone’s needs by simply adding custom data providers.
# Documentation
It’s a really painful process to keep API documentation up-to-date so we decided to make TzKT code self-documenting (by using Swagger, Open API 3), which means that the documentation is generated automatically and we don’t have to care about it.
# Resources consumption
When caching is disabled, the API server consumes about 150MB RAM (excluding high load) and about 400MB RAM when all accounts are cached (without related entities such as operations, etc). So it’s pretty cheap to use TzKT API in the cloud.
TzKT API is safe to deploy and expose to the public network as is, but it’s still recommended to use a reverse proxy such as Nginx or Apache.
# Conclusion
Well, we have just described basic TzKT concepts, its architecture and core components, indexer and API. As you can see, it is really lightweight, pretty flexible and scalable. Honestly, this is just the beginning, since only the initial functionality has been implemented, but it works! There is a lot of work to be done and a lot of features to be added, and we will do our best to achieve everything planned in a short time.
The source code of the project, released under MIT license, can be found here. Any participation through making pull requests or creating issues is highly appreciated! Also, we are always glad to see everyone in our telegram chat and happy to discuss everything related to our projects.
# Following steps
We plan to take the following steps in the near future:
- Publish a guide on how to build and deploy TzKT Indexer and API server;
- Release the first version of the explorer web interface with a couple of sweet features.
After that, we will continue to work on extending the indexer functional and API endpoints, as well as improving the explorer UI.